In this article, we will dive into the linux file systems, from the different format, its structure, the file types and some facts about partitions and mounts.
My lab is running on a Centos 9 Stream, which came out this very month. Most of this will apply to Linux distribution, I will not cover Unix or Windows command.
Definition
From TLDP: A simple description of the UNIX system, also applicable to Linux, is this:
“On a UNIX system, everything is a file; if something is not a file, it is a process.”
This statement is true because there are special files that are more than just files (named pipes and sockets, for instance), but to keep things simple, saying that everything is a file is an acceptable generalization. A Linux system, just like UNIX, makes no difference between a file and a directory, since a directory is just a file containing names of other files. Programs, services, texts, images, and so forth, are all files. Input and output devices, and generally all devices, are considered to be files, according to the system.
In order to manage all those files in an orderly fashion, man likes to think of them in an ordered tree-like structure on the hard disk, as we know from MS-DOS (Disk Operating System) for instance. The large branches contain more branches, and the branches at the end contain the tree’s leaves or normal files. For now we will use this image of the tree, but we will find out later why this is not a fully accurate image.
This way of thinking in tree is redundant in OOP (Metholds are held by Class that implements Interfaces), blockchain or version control (Git branches).
Different file system
Before storing any data on your file system, your storage device must first be formatted to a type understood by the operating system. There is too many formats to name them, but we can start with the most popular ones:
- F2FS
- Ext4
- XFS
- Btrfs
They all have their perks and defaults (stability, performance, OS support, etc.), you will use one depending on your usecase, there is bad and good answers as long as they are reasoned.
We can check our own file format with fdisk 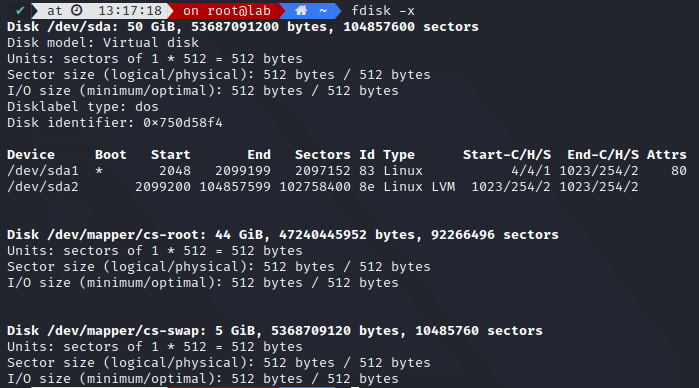
And check on a specific partition which format to use is available: 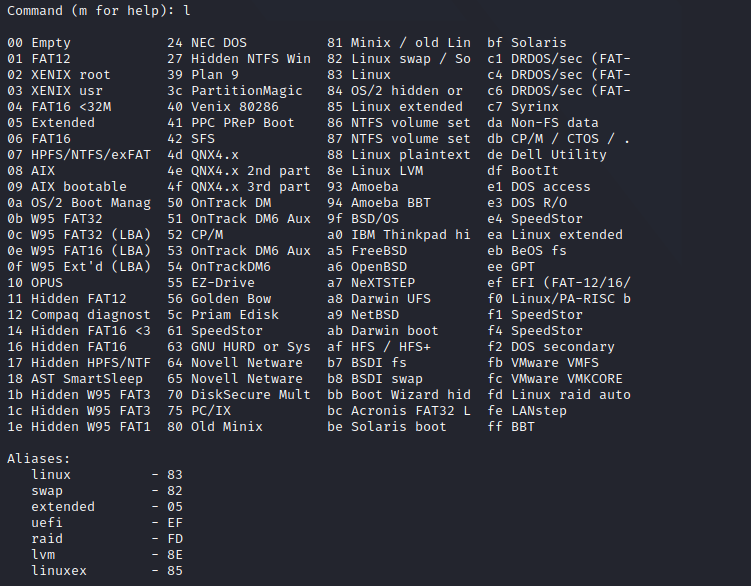
Flash media (F2FS)
Without diving too deep, all you need to know is there is two types of flash memory: NOR and NAND logic. They share the same cell design, but are connected differently, which makes NOR able to random access and NAND restrained to page access. This makes NOR 60% physically larger than NAND flash. As a result, NOR is better for reading but worse for storing data, while NAND is quick at writing but less endurant.
Now that you know that, you will understand why a specific file system format is better for some storage device than others.
Let’s say you have a NAND flash memory-based storage devices like a SSD or SD Card. It is not surprising as they are becoming the most used storage device for servers and mobile devices due to their speed, noise and reliability. From what we just learned, they are quick to write into, but last less time. Can we use a file system that address their issues while supporting its strenghts ?
That’s what Samsung did with F2FS, but It is hard to predict if they will become the most common filesystem for flash devices.
Ext4
This filesystem format stands for Extended File system and It is the default one in recent Linux. It is backwards compatible with former iterations (ext3, etc.) and useable in Windows 10 since 2016 and macOS through extFS.
It released in 2008 and has stood as one of the most used file system format for more than a decade now. Google is one of their main users since 2010. This is why It is the default format for android phones today. My (humble) guess is ext4 will slowly (~ 10 years) decline to make room for more modern file systems format.
It supports up to 1 Exabyte volumes (1000 To) and file size up to 16 Terabytes (TB).
XFS
This format will probably overthrow ext4, as It was built for performance and is mainly used on storage that are constantly reading and writing data.
To compare it with ext4, XFS supports up to 16 Exabytes volumes and 8 Exabytes file size (i.e. 16 times larger and 500 times larger than ext4). It also is optimized for quicker crash recovery thanks to its metadata journaling.
It is supported by most operating systems, and can be used in google cloud for container-optimized OS.
BtrFS
As the last file system format we check, with previous ones focused on flash, wide-support and performance, we will study one mainly used for long-term storage (for NAS, etc).
It includes snapshots and self-healing mechanisms. Facebook is one of their users, much like Parrot project and Tripadvisor. It is the least popular ones among the four, as It is one of the most recent (~ stable as of 2013). As soon as people starts to use it and understand the snapshot perks, It might gain more traction in the future.
Linux file system structure
Now that we have seen some filesystem format, we can focus on the linux file system structure.
Once you decide on F2FS, ext4, XFS or BtrFS format, linux will build its directory tree. It is defined by the FHS (Filesystem Hierarchy standard) but It is a “trailing standard” for most distributions.
For example, all Linux distribution share the same root directory called / and essentials binaries needed in single-user mode are located in /bin. But they don’t all possess a /run directory.
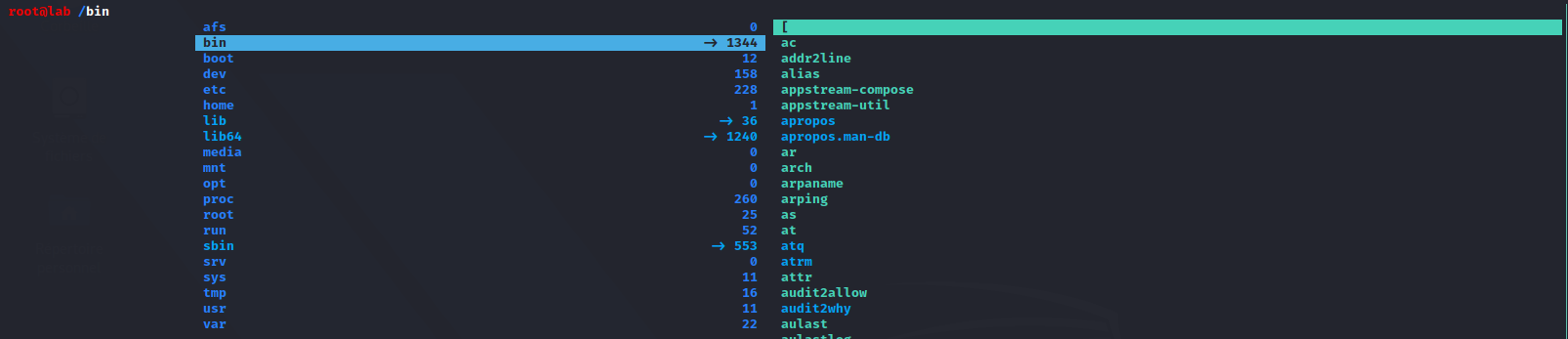
In CentOS 9:
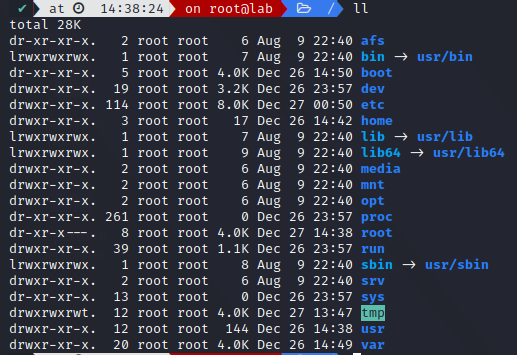
Note All symlink (bin, sbin, lib, lib64) points to /usr
Let’s check each subdirectories, and understand what type of files we could find there
Useful tools
To help us navigate through this filesystem, we can use some nice external utilities that nicely print file systems like:
- nnn (C based)
- xplr (made in Rust)
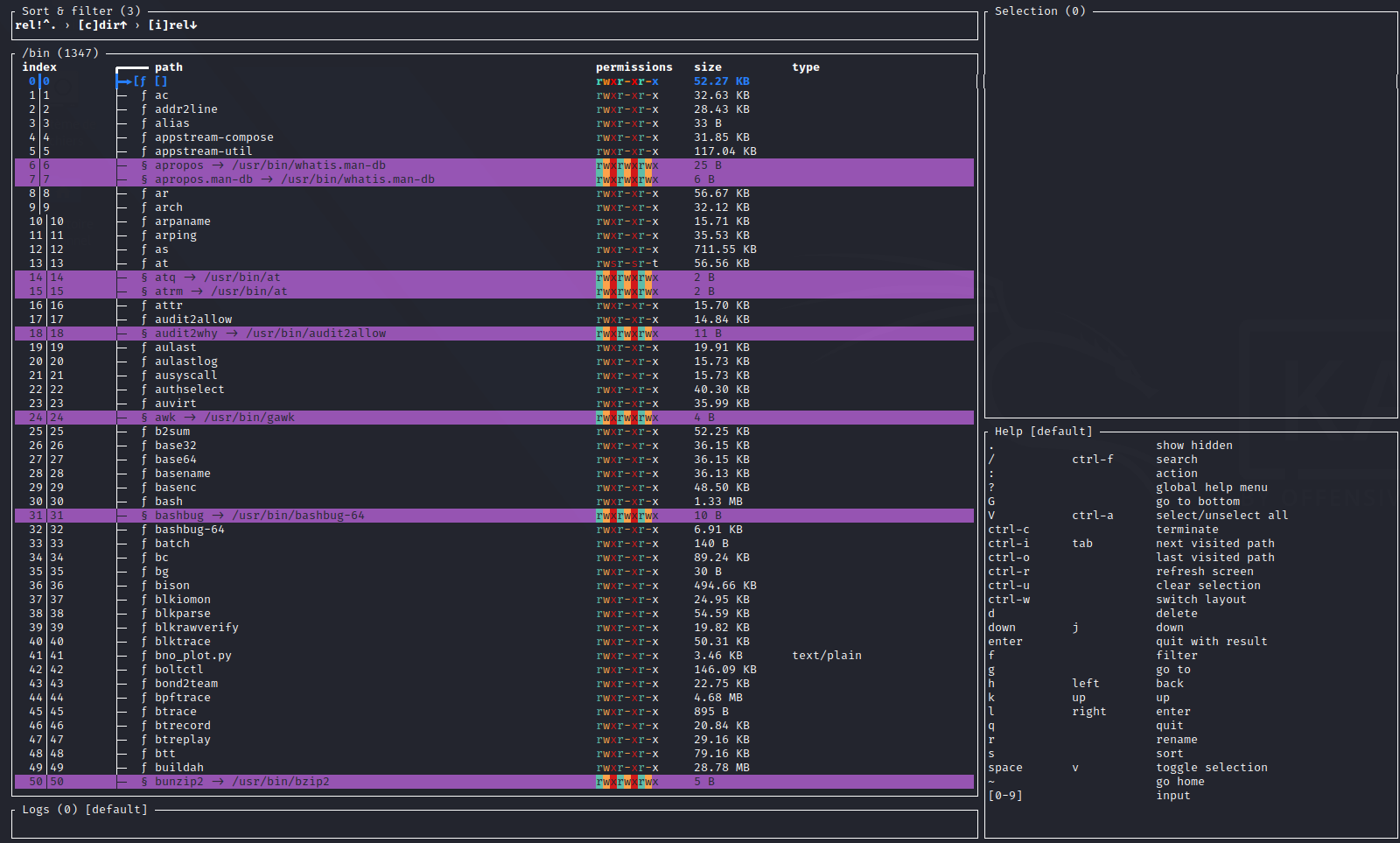
- midnight_commander (C based)
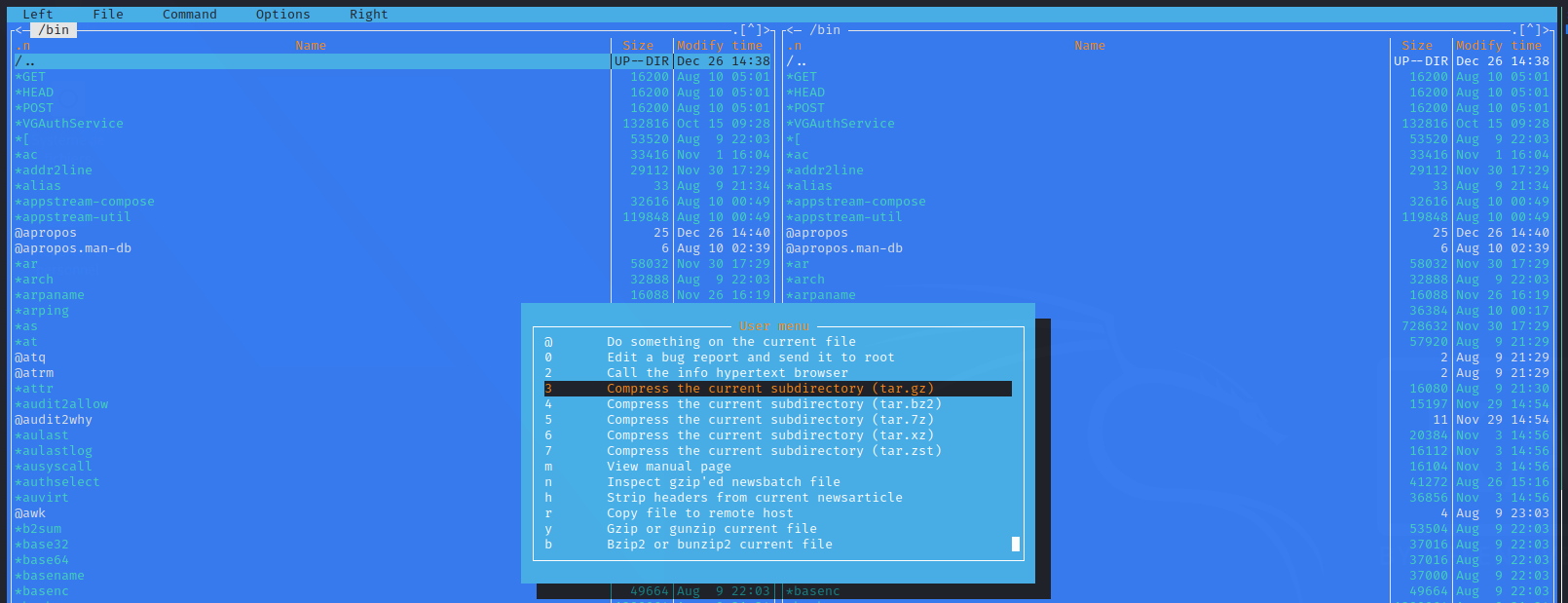
- ranger (made in Python)
These tools are optional, but they can help having a better top-level view of the structure.
Root subdirectories
| Subdirectory | Description |
|---|---|
/bin | Contains binaries (Over 260M and 1300 files), this directory has evolved overtime. In the past, It contained the minimum number of binaries needed to operate the system (like busybox). Now, It’s merged with non-essential binaries (multi-user mode), and /bin is just a symlink for backwards compatibility. You should never install a binary here, only the ones provided by the OS. Prefer using /usr/local/bin |
/boot | Contains boot loader files responsible for booting the server (efi, grub, loader and the kernel vmlinuz), this directory is critical for loading linux on reboot |
/dev | Stands for device, lists references to all CPU peripheral hardware, which are files with special properties, tty are for terminals (USB, serial port), sd for mass-storage driver, mem for main memory, hd for IDE driver, and pt for pseudo-terminals. There is three types: character, block and pseudo devices. |
/etc | Host-specific system-wide configuration files, It only contains static files. One notable subdirectory is /etc/opt used for add-on configuration packages |
/home | Users home directories, containing all their saved files and settings |
/lib | Libraries used by binaries and compilers (like libncurses or motd). You can check what libraries a binary uses with ldd command |
/media | Mount points for removable media such as CD-ROMs, USB drives |
/mnt | Temporarily mounted filesystems, you can create mount points anywhere in the system, but It is standard convention (and sheer praticality) to not litter the file system with randomly placed mount points |
/opt | Used for third-party application without dependency outside of their package, It is supposed to be self-contained |
/proc | Virtual filesystem (only available at runtime) providing process and kernel information as files, usually a procfs which create a hierarchical file-like structure used to dynamically access process data held in the kernel without using tracing methods or direct access to kernel memory |
/root | Home directory of your system boss (root user) |
/run | Recent subdirectory, It holds run-time variable data. It contains information about the running system since last boot, like currently logged-in users and running daemons. They are removed or truncated at the next boot process |
/sbin | Contains essential system binaries, used for maintenance or administrative tasks. Locally installed binaries should be sent to /usr/local/sbin. We may find fdisk, lilo, init, ip, and interestingly enough, we may find some these binaries in /etc in older distributions |
/srv | Holds site-specific data which is served by the system (ftp, rsync, www, cvs) |
/sys | It is a virtual file system that can be accessed to set or obtain information about the kernel’s view of the system. It is different from /dev as the latter contains the actual devices files without going through the kernel, while /sys is an interface to the kernel, much like /proc. It contains informations on drivers, busses, network and much more. Also /proc is older and less structured. |
/tmp | Contains files that are required temporarily, like lock files. It is one of the few subdirectory of / that does not require to be superuser |
/usr | Usually contains by far the largest share of data on a system (Here 3G). It contains user binaries (in /usr/bin), libraries (/usr/lib), etc. It is deemed as shareable, read-only data and must not be written to. Any information that is host specific or varies with time is stored elsewhere. |
/var | Contains variable data like system logging files, mail and printer spool directories. Some portions are not shareable between systems, like /var/log or /var/lock, while other may be shared, like /var/mail or /var/spool/news. |
Some directories are more critical than others, and can be put onto separate partitions or systems, for easier backup, due to network topology or security concerns.
‘Mountable’ (Non-critical) directories are: /home /mnt /tmp /var Essential directories for booting are : /usr /boot /dev /etc /lib and /proc
File types
Now that we know what each directory purpose is, we can take a look further into the file system. After directory comes files, so let’s check each of them !
Before diving deeper, we need to understand the concept of inode
Inode
Linux filesystems are hard to understand, especially for a computer working with 0 and 1. How does our system understand its structure ? That’s when an inode is essential, It’s an index node that describes the file attributes such as the physical location on the hard drive, permission privileges, in short all the metadata that we know of a file. It is stored separately from the files themselves. Each filesystem generate its inode stable to identify each file It holds.
For every file on your file system, there is an inode containing 16 KB of this file metadata. We can check this number with df
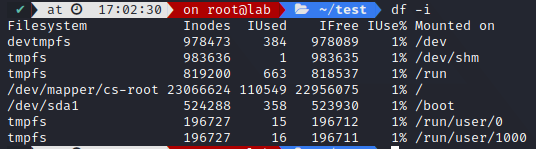
How do we check a file’s inode ?
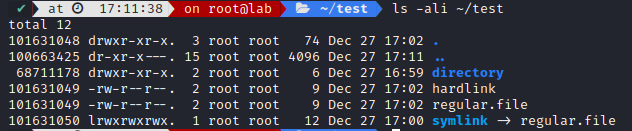
Here we can see each file types possess an inode, even links or directory.
Of course there is more advanced operations available on an Inode, but know for example that an inode structure depends on its file type, like a directory holding a list of inodes of the files It contains.
Regular file
A regular file can be created with touch and have no special attributes

Directory
We can create a directory with mkdir which can be later recognized with the attribute d

And we can check its inode and file attribute with stat
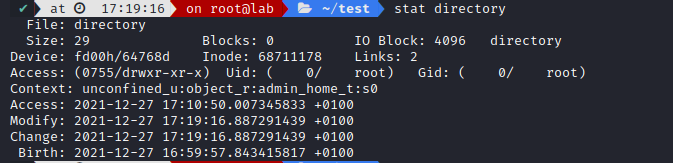
Link
Links are created with ln, and there is two types:
- Hard link (default) - the new file will share the inode number with the original file
It is only possible to hardlink a regular file, not a directory.

- Symbolic ( -s parameter) - It creates a new file (with its own inode) pointing to the original file address

Symbolic links can be applied to all types of files.
And if we try to access its contents, It makes it appear as if we are accessing the real file:
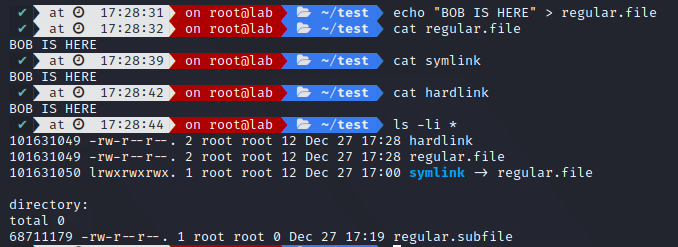
Notice how the inode is identical on the regular.file and hardlink (101631049) but different on the symlink (101631050)
If the original file (regular.file) was to move somewhere else, the symlink would break (as the file address changed), but the hardlink would still point to the file as It retains his inode.

Whether we move the file, or change its content, the hardlink will still access the right file content

Hardlinks will only break if the file is moved to another volume.
While symbolic links will only break if the original file is moved or deleted, but It can be used to reference across volumes.
Hardlinks are less and less present in Linux, as they mostly shift towards symbolic links, but can still be encountered in smaller distribution like BusyBox, as It saves space on the drive.
Special file
Also named device file, It is an interface for a device driver that appear in a file system as It It were an ordinary file. They are three types:
- Block devices - works with fixed-size blocks (see buffers) and large output of data, such as with a hard-drive
You can find them with lsblk
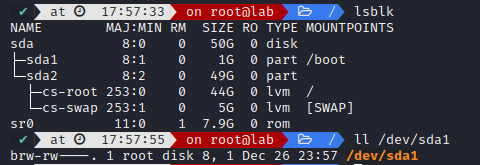
- Character devices - can only send one character at a time, pratical in an internet connection I could not find any command for finding characters devices (unless you want to search the entire file structure), but you can find them in /sys/dev/char/

- Pseudo-devices - It is a device driver without an actual device
They serve pratical purpose, like a virtual sinkhole, or producing random data
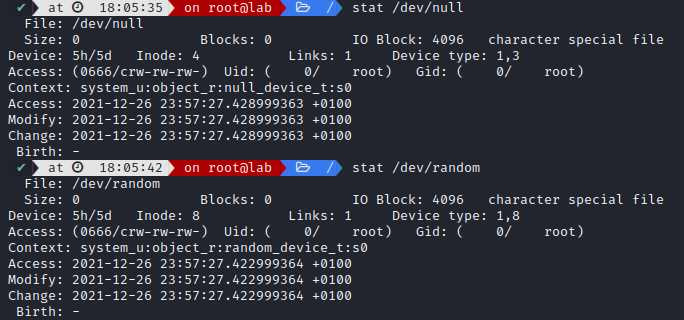
Socket
Sockets are used to communicate between programs. There is two types:
- Stream sockets (using TCP as their underlying transport protocol)
- Datagram sockets (using UDP)
- Unix Domain Sockets (Using IPC - SOCK_STREAM)
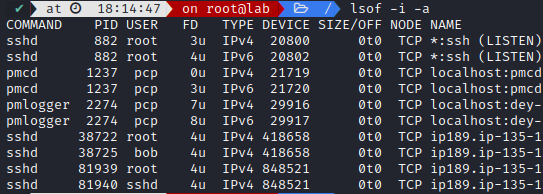
You can find them by checking your opened sockets with ss (netstat replacement) in /proc/{PID}/fd

Or look for open files with lsof
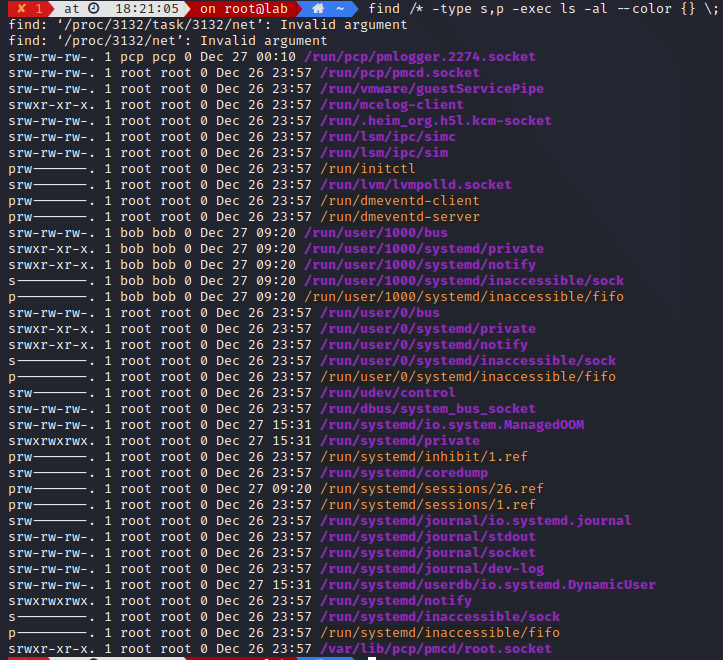
Alternatively, you can use find on specific file type (here named pipe and sockets)
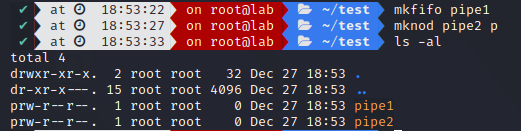
Named pipe
A pipe has a read end and a write end. Data written to the write end of a pipe can be read from the read end of the pipe.
As opposed to unnamed pipe, like the one to string together commands like

A named pipe, also known as First In First Out, is similar to a pipe but with a name on the filesystem.
Processes can access this special file for reading and writing, and provides bidirectional communication.
It is created with mkfifo and mknod (p for FIFO)
And now we can simply use them to transfer data by specifying the pipe name. Here we use two shells, one for sending the data, the other to receive and compress it.

Partitions
A hard disk can be divided into several partitions that will function as If It were a separate hard disk. The idea is that if you have one hard disk, and you want two operating systems on it, you can divide the disk into two. This information is stored in its first sector, also called Master boot record (MBR), of the disk. This is the sector the BIOS reads in and starts when the machine is first booted. This MBR contains the partition table to check which partition is active (i.e. bootable) and reads the partition’s boot sector (in case of Linux, its /boot)
We can list our partitions with lsblk
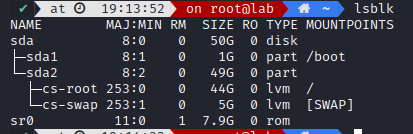
We can see our disk sda is split into two partitions:
- sda1 (containing the first sector /boot)
- sda2 (containing our 49G data and swap)
- cs-root (containing our / filesystem)
- cs-swap (containing our swap volume)
Disks are automatically named sd{a..b..c…z}
LVM just means logical volume manager, used to create logical storage volumes with greater flexibility than partitions, such as resizeable storage pools to extend or reduce the volume size without reformatting or repartitioning the underlying disk devices.
Also, a partition can be a primary partition of extended partitions. Consider just main partition and sub-partition if this vocabulary is too complex, they were just made like this because original partitioning scheme for hard disks were limited to four (primary) partitions.
Data partition
Considered a normal Linux system data, including the root partition containing all the data to start up and run the system
We will often find a few partitions on the system:
- / ~ 3-5 GB+ and only ext4 on RHEL distrib
- /boot ~ 250 MB+ and only ext4 on RHEL distrib
- /home ~ 100 MB+
Swap partition
Expansion of the computer’s physical memory, they are used to support virtual memory, and data is written to a swap partition when there is not enough RAM to store the data your system is processing.
Over the past decade, the recommendend amount of swap space increased linearly with the amount of RAM in the system.
The recommended swap space is as follow:
| Amount of RAM in the system | Recommended swap space |
|---|---|
| < 2GB | 2 times the amount of RAM |
| 2-8GB | Equal the amount of RAM |
| 8+GB | At least 4 GB |
Mounts
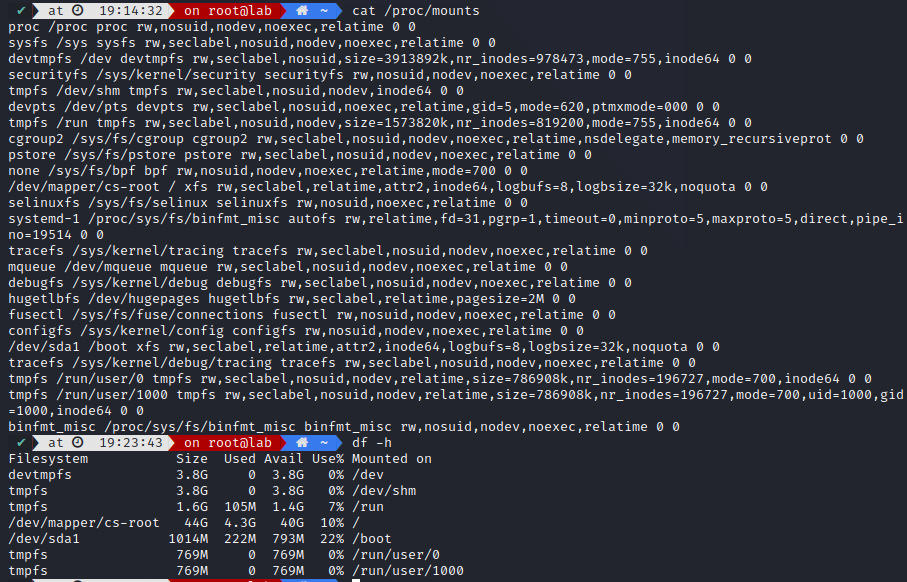
All partitions are attached to the system via a mount point. The mount point defines the place of a particular data set in the file system. They can be connected anywhere on the file system, but It is bad practice to do it outside of root subdirectories.
You can check your partition in /proc/mounts or through df utility
To go further
We covered formatting the filesystem through different format, partitioning it into logical volumes to then be mounted onto your file system, which handles different files types through inodes and binaries.
There was a lot to uncover, and I was not expecting it to take this long, but I wanted to give a full picture of what file system are like, from the storage to its terminal.
Each filesystem format has their own implementations, and could be interesting to check at a low-level. We could perform a write/read tests to check which ones are more performant.
There is a lot of commands available to play with files in Linux, like sed/awk/grep/sort/cut, and they will be covered in a later article.
Check out some links below to dive deeper into the subject.
Credits
https://linuxiac.com/linux-file-system-types-explained-which-one-should-you-use/
https://www.linux.com/training-tutorials/linux-filesystem-explained/
https://opensource.com/life/16/10/introduction-linux-filesystems
https://tldp.org/LDP/intro-linux/html/sect_03_01.html
https://en.wikipedia.org/wiki/Flash_memory
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/9-beta